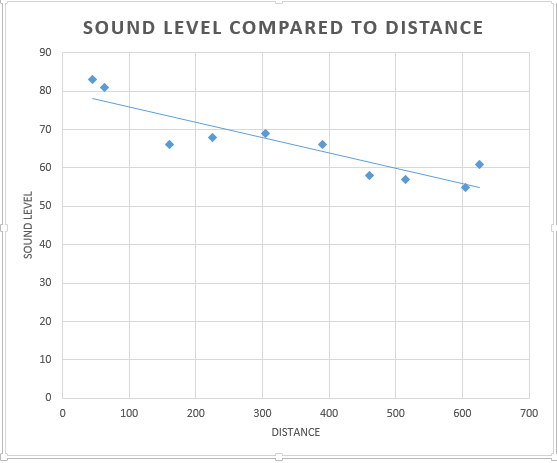
The claim that as crime rates increase so does the amount of children receiving free lunches that was made by the news is correct in this statement. When running a regression analysis on these two variables the data suggests that yes there is correlation between the two where with the increase in crime rates there is also a high incidence of free lunches given out to children in schools. But if you look at the r squared value for this relationship it is .173 meaning that the two variables don't really explain each other very well meaning that the relationship is a spurious one. With this analysis one could be 99.5% sure that yes these two variables correlate but the relationship is spurious. Based off this relationship with a crime rate of 79.9 you could expect to have a free lunch percentage of about 40%.

Part 2
Intro
For part two the objective was to examine the enrollment numbers for UW system universities and try to determine if there was a certain variable that could be determined that would cause someone to choose one school over another. thanks to the professor the data of percent with a Bachelors degree, Median Household income and distance each county is from each school. Using this data it is expected to analyze the significance each has on a students university decision.This analysis will require use of regression analysis and mapping of the residuals received from this analysis. To complete these two tasks SPSS is required for the regression analysis and ARCMAP will be used for map creation purposes.
Methods
For this the data for the UW system was provided in a excel file containing broad information about the universities and Wisconsin counties. One of the first things that was done was normalize the population numbers for counties based on the distance from each institution. This is to help decrease the impact that larger counties such as Milwaukee county will have on the results, protecting from possible large outliers. Once this column was created the process of running linear regression analysis could begin. This is a statistical tool that used to evaluate the relationship between two variables often looking for causation in this analysis. This analysis was run three separate times examining the if income education or distance were the largest factor in choice. Each time the dependent variable being number of students attending and the the independent variable being the distance, percent having a bachelors degree or median household income. With these outputs the strength of the relationships could be determined and if they were considered significant or not. Another byproduct of these outputs was the residual creation for each individual county or how far the result for each county is from the best fit line. With these residuals, chloropleth maps could be created showing a visual interpretation of the data.
Results
 |
| Figure 1 population distance for Eau Claire |
 |
| Figure 2 percent bachelor degree for Eau Claire |
.PNG) |
| Figure 3 Median household income for Eau Claire students |
.PNG) |
| Figure 4 Population distance from county for River Falls |
.PNG) |
| Figure 5 percent bachelors degree for River Falls |
 |
| Figure 6 Median Household income for River Falls |
 |
| Figure 7 residual map for Median Household income for River Falls |
 |
| Figure 8 residual map for population distance for Eau Claire |
 |
| Figure 9 residual map for percent receiving a Bachelor degree for Eau Claire
For this analysis the schools of UW Eau Claire and UW River Falls were chosen as the study area. Figures one through six are the SPSS outputs for both schools independent variables that were analyzed. The first thing analyzed was the population of the schools coming from each separate county normalized by distance from the institution. For UW Eau Claire the regression analysis produces a significance of .000 meaning that it is almost one hundred percent certain that there is correlation between population of the university and the distance they originate from. This is echoed by the the R square value of .945 so the two variables describe each other very well. This is in stark contrast to the same variables for UW River Falls where the significance of .776 and an R square of .001 meaning that the relationship between the two are neither significant or descriptive of each other. The second variable being examined is the percent of students receiving a Bachelors degree( figures 2 and 5 ). For Eau Claire the significance was .003 and the R Square was .121 meaning that it is a significant relationship between the number of students attending and amount of students receiving a bachelors degree and the two variables do not describe each other very well. The returns for River Falls were interesting to where the data has a significance of .105 but, for the purposes pf this analysis a significance level of at least 95% is required. But an interesting part of this return data is that even though the significance level is to high to be considered significant for this the R squared value is .037 meaning that the two variables do not explain each other very well. The final variable that was examined was the Median household income for counties. For Eau Claire the return produces a significance of .104 and an R square value of .037 meaning that the data is about 90% significant but is not significant enough to be relevant for this analysis but the two variables do not explain each other very well. This variable did in fact though describe the data set for River Falls well where it produced a significance of .028 and an R squared of .067.
Conclusions
The goal of this assignment was to determine if there is a variable that could be identified that lead to a students choice in university attended more than usual. The three variables that were examined percent of the county with a bachelors degree, Median Household income of the counties and the total population of the county normalized by the distance from the institution. For percent of county with a bachelors degree this variable was only truly descriptive for Eau Claire with the low significance and R squared values meaning that the two variables describe each other well. For Median Household income this seemed to only be a significant relation ship for UW River Falls. For the third variable which is population of county in relation to the distance away from the university was descriptive for UW Eau Claire with the high R square and low significance value. Based on this there is not enough evidence to say that there is one concrete variable that influences the decision of a student to choose a university.Though for each university there is one variable that was examined that was deemed significant in the decision to choose which university in the end it is ultimately the choice of the individual on where they will attend.
|